


Last Commit: 2024-01-06 17:50:27
views:
Web Performance
从why, how, what三个纬度去讨论下前端性能监控这件事。
Why
全球趋势
在讨论之前,我们可以来看一下,一些制约前端性能的因素,在全球的一些情况:
网速

可以看到,mobile端的网速上升的比固定宽带的快很多,但是从绝对值上来说,仍然是很慢的,从很长的一个时间段上来说,mobile端的加载速度,仍然是比起来相对慢的。
文件大小

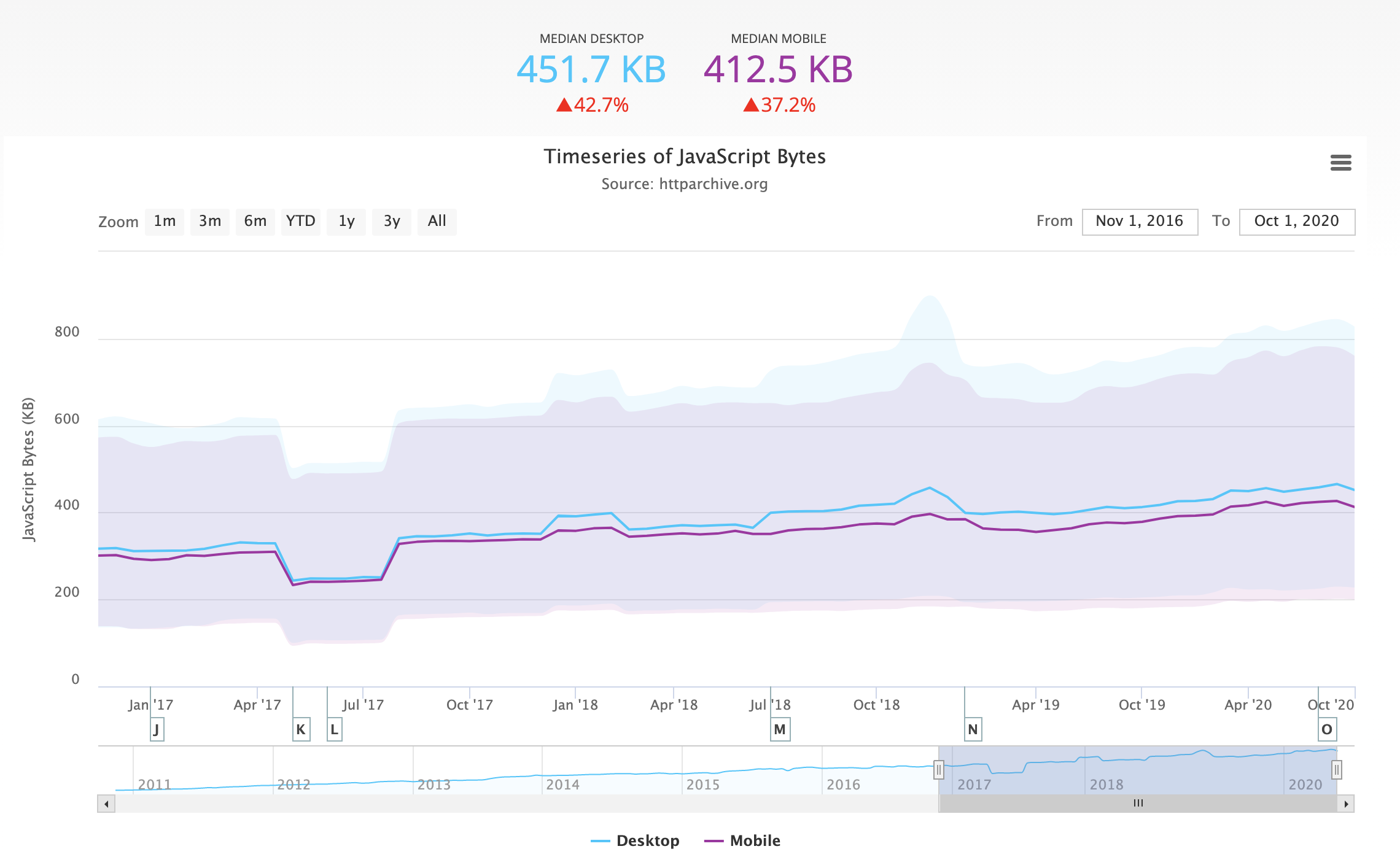
从中可以看到,web的静态资源体积是总体一直在上涨的,其中js的上涨速度尤其的快。
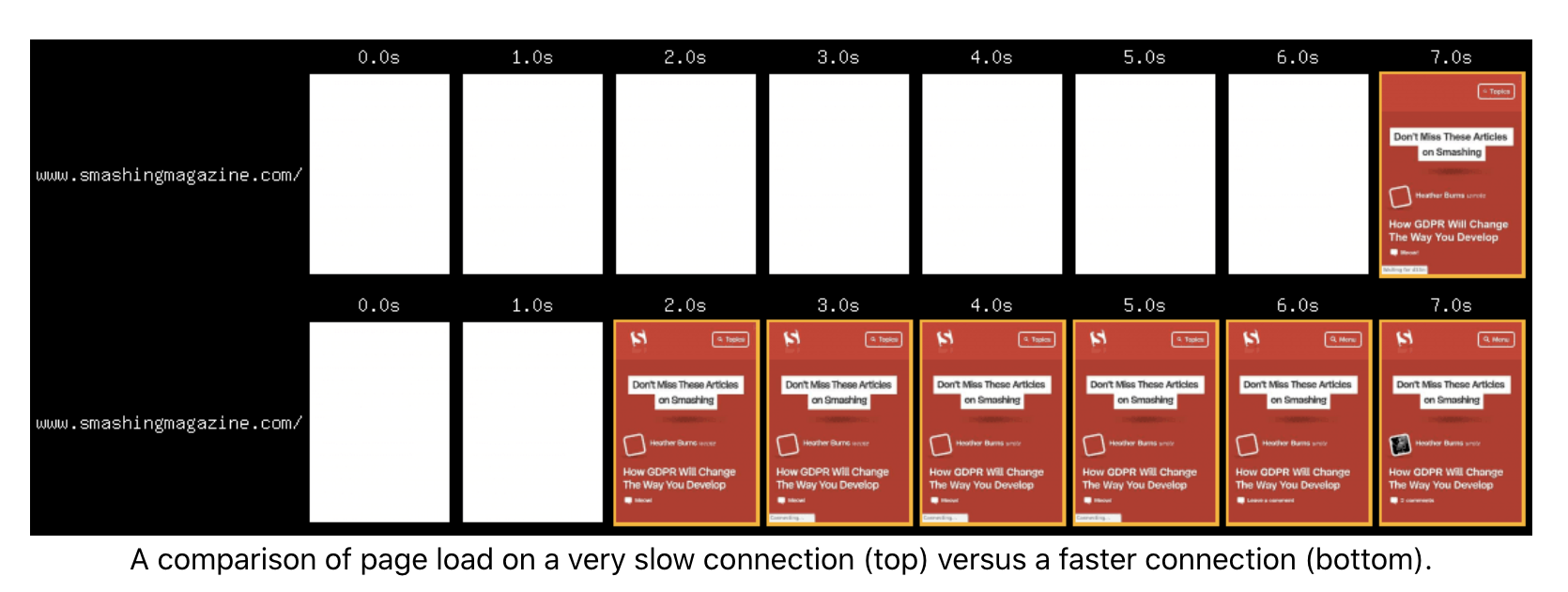
首屏时间
可以参考这个报告:
https://httparchive.org/reports/loading-speed
可见,即使文件体积变大了,全球网站的响应速度仍然是越来越快的,如果跟不上这个发展,那我们的网站表现的就会尤其扎眼。
性能和留住用户的关系
更快的打开速度和用户流量和注册率的关系
- Pinterest reduced perceived wait times by 40% and this increased search engine traffic and sign-ups by 15%.
- COOK reduced average page load time by 850 milliseconds which increased conversions by 7%, decreased bounce rates by 7%, and increased pages per session by 10%.
- The BBC found they lost an additional 10% of users for every additional second their site took to load.
和用户转换率的关系
- For Mobify, every 100ms decrease in homepage load speed worked out to a 1.11% increase in session-based conversion
- AutoAnything reduced page load time by half, they saw a boost of 12% to 13% in sales.
- Retailer Furniture Village audited their site speed and developed a plan to address the problems they found, leading to a 20% reduction in page load time and a 10% increase in conversion rate.
一些对于首屏的改进,对用户体验提升明显
衡量的方式
对于不同的页面,我们可以有不同的衡量方式
- 对于主要用于展示的内容页,我们可以用syn的方式,比如lighthouse,做提前的检测
- 对于重交互的页面,比如登录表单之类的,我们可以用rum的监测,来记录到底用户体验如何
How
监控什么
首先我们需要知道应该监控些什么呢?有哪些具体的指标?
一个页面被打开有很多阶段,这些阶段,既不一定存在,也不一定连续。如下:
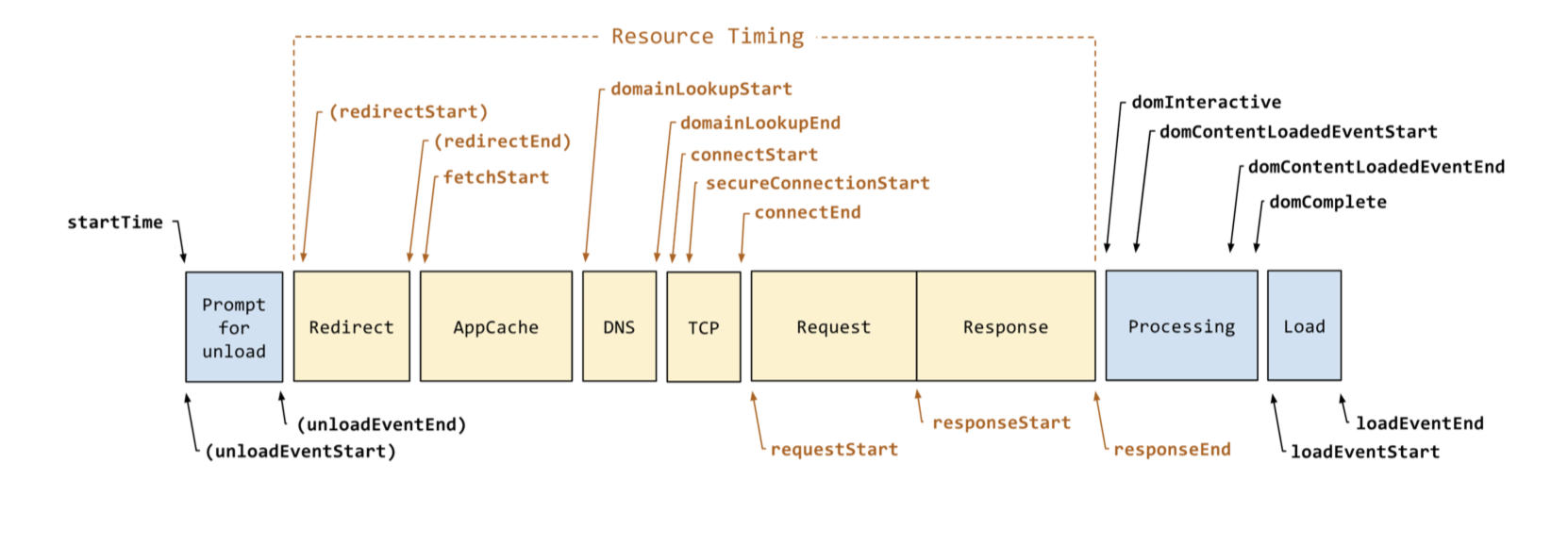
Google有RAIL模型和Progressive Web Metrics标准去衡量一个页面的表现。从中我们可以提炼出一些关键性的指标。
- 性能指标:加载呈现又快又稳。加载到展现的性能指标和稳定性指标。
- 秒开率:页面首屏加载时间小于1s的比例,也就是页面加载到onload事件触发时所消耗的时间。
- FP(first paint) 和 FCP(first content paint) 分别是指页面首次绘制和首次内容绘制。
- FMP(first meaningful paint)首次有意义绘制, 是页面可用性的度量标准。自定义程度比较高。TODO.
- TTFB(time to first byte, 首字节时间),是指从浏览器发起第一个请求到数据返回第一个字节所消耗的时间,这个时间包含了网络时间,后端处理时间等等,可以作为一个链路数据综合参考指标。
- 稳定性指标:先知已经覆盖大部分场景,这里做两个补充:
- 白屏: 监测在无异常抛出的情况下的白屏。
- 资源错误:静态资源加载错误,常见的就是404,资源地址不正确或者远程服务有问题。
- 体验指标:操作反应灵敏。点击,滑动等交互响应及时,操作流畅,动画运行流畅。
- 响应延迟:用户点击后页面没有响应或者响应时间超过100ms,用户感觉这次点击操作是延迟的。
- 卡顿:统计浏览器中执行时间超过 50 ms 的任务,都是 longTask,可能会造成页面卡顿。
- 滚动流畅性:滚动过程是否流畅,监测用户开始操作到页面开始滚动的时间差,按照前面的标准,小于100ms才会体验流畅。
- TTI(time to interactive, 可交互时间):指页面已渲染出内容,同时可以响应用户的输入的时间。
- FID(First Input Delay),首次输入延迟,用户首次和页面交互到页面响应交互的时间。一般都是因为主线程阻塞,会导致响应慢。这个指标反映用户对当前页面的第一感觉,比如html渲染出来一个输入框,用点了输入框页面却没有响应,卡了一下才能输入内容,这个卡的时间就是FID。
实现主要依赖了Performance接口,它允许访问当前页面性能相关的信息。它是High Resolution Time API的一部分。但是它被Performance Timeline API, the Navigation Timing API, the User Timing API, and the Resource Timing API 扩展增强了,实际上Performance的主要功能都是由这几个API提供的。
除了专业维度,还有常规维度也是我们要一起收集的。只有这样,我们才能知道这个页面的具体情况。
- 基本信息
- url,浏览器,操作系统,时间等
- 页面加载方式,是直接打开,还是刷新打开,还是前进后退打开等等
- 是否启用 HTTP2、Service Worker
SYN vs RUM
从技术方面来讲,前端性能监控主要分为两种方式,一种叫做合成监控(Synthetic Monitoring,SYN),另一种是真实用户监控(Real User Monitoring,RUM)。
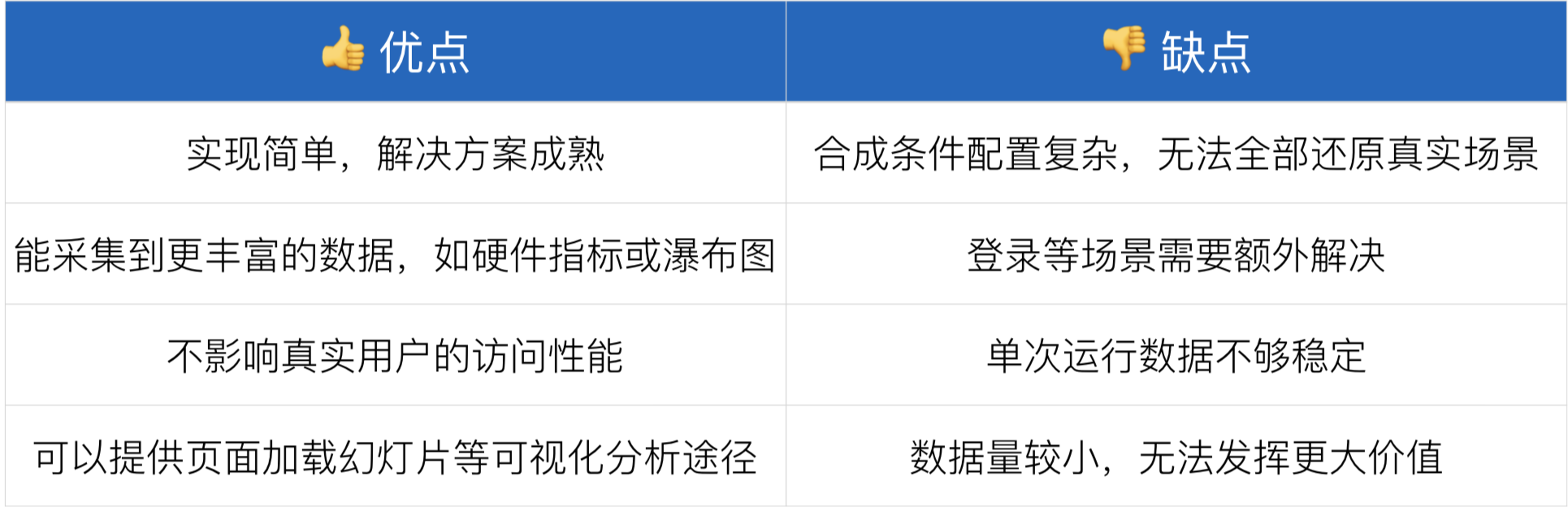
SYN就是在一个模拟场景里,去提交一个需要做性能审计的页面,通过一系列的工具、规则去运行你的页面,提取一些性能指标,得出一个审计报告, 比如Google 的 Lighthouse。优缺点如下:
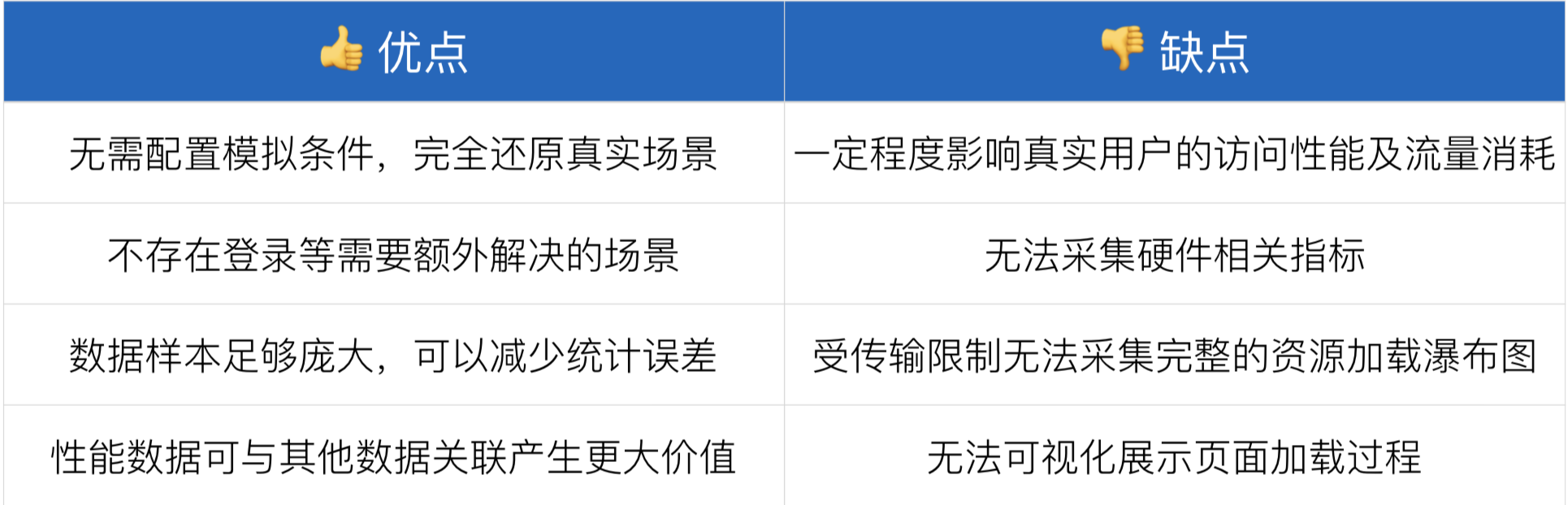
RUM就是用户在我们的页面上访问,访问之后就会产生各种各样的性能指标,我们在用户访问结束的时候,把这些性能指标上传到我们的日志服务器上,进行数据的提取清洗加工,最后在我们的监控平台上进行展示的一个过程。优缺点如下:
我们来对比一下:
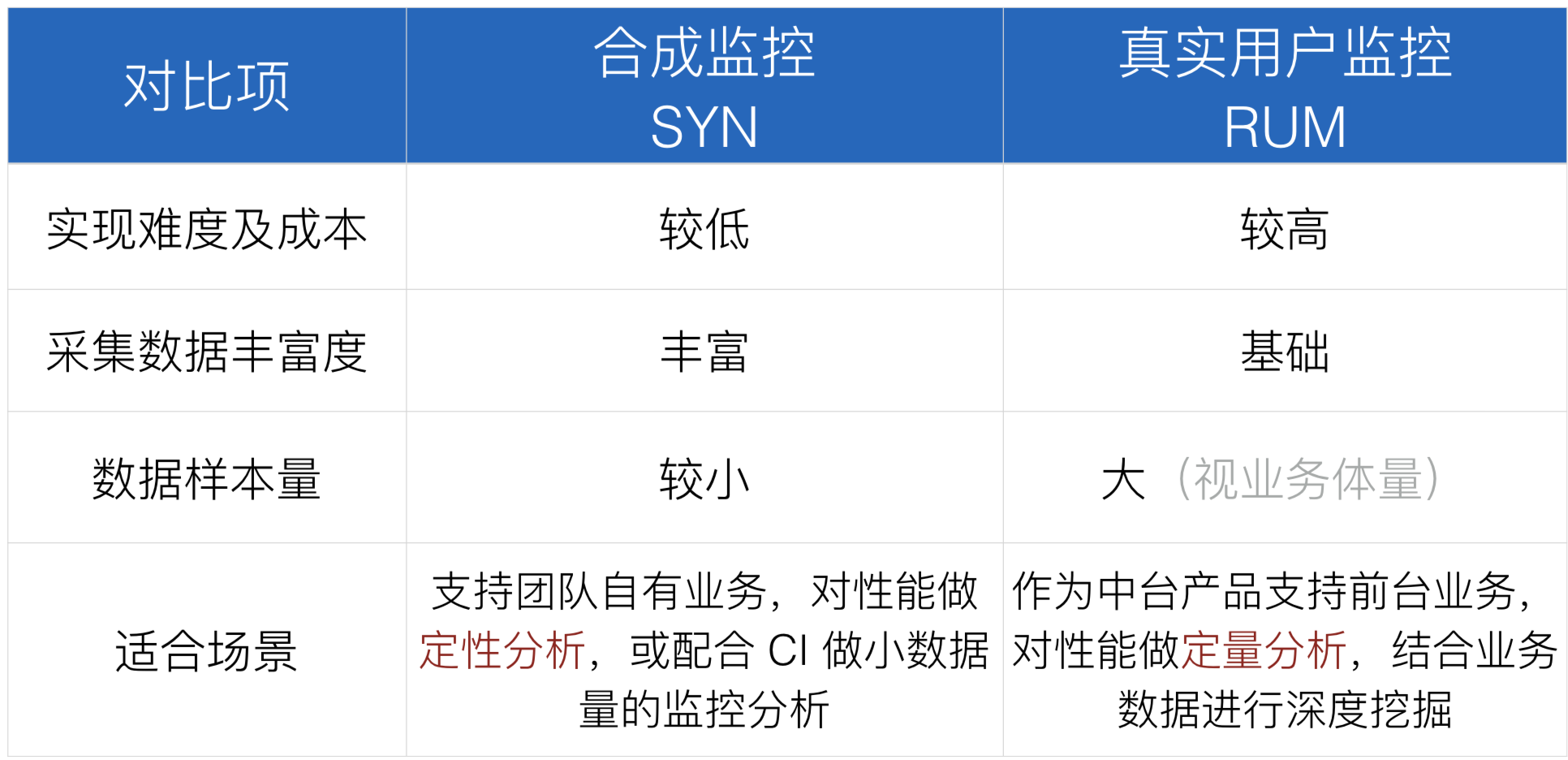
个人认为,RUM是更适合中台前端去做的,能定量分析页面,可定制化添加一些额外功能比如报表和告警,也容易有沉淀。
量化分析
在量化数据的展示上坚持一个原则:以90%位数为准。这个数字意味这什么呢,意味我们可以承诺90%的用户是可以满足这个数据的。
比如,fp时间90%位数是1s,我们就可以承诺90%的用户的初次渲染时间在1s内。
相比于容易受影响的平均值,这个数字可以帮助我们更好的去总结一些结果,作为作出重要承诺的一个依据。
在量化分析上,提供了首屏,体验分和load静态文件资源这三个维度上的量化。
- 首屏
包括各种首屏参数,和不同时间段内的对比。
- 体验分
给出了一个综合的体验,对一些对前端页面没那么熟悉和匆匆一看的开发人员,可以提供一个大致的结果。
- load时静态文件资源
即为load时的静态文件资源信息,会和上一个有数据的日期比较,得出一个变化比例。同时,会根据文件大小和传输大小,计算出缓存率。
值得一提的是,有时候可能传输大小比文件大小还大,比较隐晦的判断依据如下:
- 200本地缓存,0 transferSize,full encodedSize
- 304, a little transferSize,0 encodedSize
- 200, full transferSize,full encodedSize
性能体验
在性能体验上对谷歌rail模型的实践。同时,这种即时互动性能体验,也是rum监控区别于syn监控的最大不同。
Response
正如谷歌所言,如果interactions超过了100ms,用户就会感到操作是不连续的。
所以在响应延迟中,会记录包括点击和滚动的延迟时间。有三个图表可以帮助找出响应延迟事件出现的频率趋势,distinct和比较突出的响应延迟事件。
同时,会根据fps,设备电量,异步请求等信息,给出一些可能的原因。
AnimationandIdle
这两块谷歌分的比较细,要求也比较高。fps要求高达100,idle时间超过50ms,可以保证用户体验达到丝般顺滑,当然我们的要求可以适当低一些,fps在50就差不多了,再低用户感受可能就很不好了。
会分别记录button点击和滚动屏幕两种时间:
如果一个用户点击一个
button, dom tree超过100ms没有任何变化,会记录为一次点击响应延迟时间,同时记录期间发生的异步请求和渲染记录。在用户滚动屏幕时,记录期间内平均fps和最低fps,如果低于设定值,记录为滚动响应延迟时间,同时记录期间发生的异步请求和渲染记录。
这两种是特别典型的场景,可以帮助前端同学找出最影响用户体验的地方。
Load
基于谷歌的心理学分析,如果一个页面超过5秒不可交互,那用户gone的可能性就大大增加。当然对于千寻的业务,其实影响不那么大,真的有人有会冲动消费定位服务吗。
但是,这个部分相当体现前端的价值,因为load时间缩短,直接体现了有些优化的价值,比如缓存,合并批操作,渲染逻辑等等。具体参见首屏。
上报
在接入的sdk上报上有两个点要去满足:
- 不影响前端主项目的工作
- 减小对后端服务的压力,避免服务挂掉
流程如下:

前端在调用init只会初始化一个Reporter类,在接下来的调用中,用到了那些collect模块才会去实例化用到的模块。在long poll中收集数据,不为空的话才会批量压缩用Image Beacon上报。
后端只存disk返回204,然后定时任务逐条处理。
总结一下,现在的处理方式核心理念是实时记录,后置处理。在这种设计下,可以很有信心的保证sdk在记录全面的前提下不会影响性能,后端服务不会挂掉。
更进一步,在以后的迭代中,可以直接取sls或者nginx的记录来处理分析,服务本身连disk都不用存。如果是nginx的话,甚至连收集接口都可以直接去掉,slb配置返回204,service就是纯粹的定时任务。
Reference
- https://www.infoq.cn/article/Dxa8aM44oz*Lukk5Ufhy
- https://web.dev/rail/
- https://codeburst.io/performance-metrics-whats-this-all-about-1128461ad6b
- https://developers.google.com/web/updates/2017/06/user-centric-performance-metrics
- https://github.com/d2forum/15th/blob/main/D2-19/%E4%BB%A5%E5%85%A8%E7%90%83%20Web%20%E8%A7%92%E5%BA%A6%E8%B0%88%E5%89%8D%E7%AB%AF%E6%80%A7%E8%83%BD%E7%9A%84%E6%9B%B4%E6%96%B0%E4%B8%8E%E8%B6%8B%E5%8A%BF(Palances)19-3.pdf
- https://www.speedtest.net/global-index
- https://almanac.httparchive.org/en/2020/javascript
- https://almanac.httparchive.org/en/2020/page-weight
- https://httparchive.org/reports/state-of-the-web
- https://web.dev/why-speed-matters/
- https://developer.mozilla.org/en-US/docs/Web/Performance